| 摘 要: | 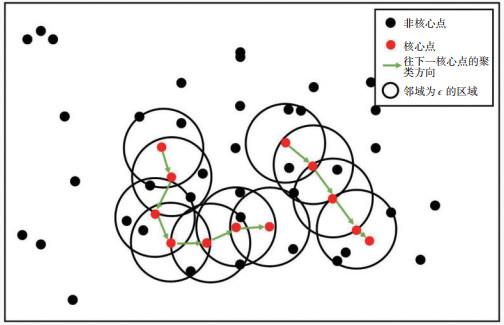
为了评估不同聚类算法对雷暴系统的识别效果,进一步提高雷电临近预报能力,本文采用地闪定位数据和雷达反射率数据,利用基于密度的空间聚类(Density-Based Spatial Clustering of Application with Noise,DBSCAN)、快速搜索和查找密度峰聚类(Clustering by Fast Search and Find of Density Peaks,CFSFDP)以及改进的快速搜索和查找密度峰聚类(Extended Clustering by Fast Search and Find of Density Peaks,E_CFSFDP)三种聚类算法,对2018年9月21日19∶15—20∶57(北京时)发生在(114°—117°E、27°—30°N)区域的一次雷暴过程进行了聚类识别计算,探讨了三类聚类算法在雷暴系统识别中的差异。
结果表明:(1) DBSCAN算法在地闪数据分布清晰且不同数据簇之间有显著距离间隔时,分类识别的准确率较高;当各个闪电数据簇的簇间距离或密度相差很大时,分类识别的准确率较低;(2) 地闪数据“无密度峰值”分布时CFSFDP算法会分裂出错误类,每个闪电数据簇仅具备唯一的密度峰值点是CFSFDP算法识别准确的前提条件;(3) E_CFSFDP算法解决了CFSFDP算法的“无密度峰值”问题,受地闪数据分布影响较小,因此基于E_CFSFDP算法的雷暴系统识别准确率明显高于DBSCAN和CFSFDP算法。
|